Exploring the CQRS Architecture Pattern: Advantages and Challenges
Written on
Chapter 1: Understanding CQRS
Software systems are designed to fulfill a multitude of roles from their inception, and over time, the demands placed on them evolve. These changing requirements can involve shifts in business logic, the need for scalability, or other elements of the system.
To address these often conflicting or overlapping requirements, engineers must navigate a variety of design trade-offs. The challenge arises because many of these trade-offs may not be apparent initially, and by the time they become necessary, the system's architecture may have progressed to a point where those adjustments are no longer feasible.
In my experience, the most problematic instances of design becoming rigid occur at the data layer. Typically, an application’s data model is shaped by a combination of domain knowledge and performance considerations. Domain knowledge determines the entities involved and their logical relationships, while performance considerations dictate their physical implementation (e.g., whether to use RDBMS or NoSQL, and the setup of primary keys and indexes). These choices work together to ensure that an application effectively meets its intended use cases.
Section 1.1: The Challenge of Diverse Data Views
In extensive applications characterized by vast amounts of data and intricate entity models, certain implementation details can become "core" over time. This can occur either through explicit decisions made by engineers or inadvertently. In such cases, new requirements may diverge significantly from the existing implementation, rendering them impossible to accommodate.
This issue encompasses a wide range of problems, each requiring different solutions. Here, I aim to focus on scenarios where the manner in which data is read diverges sharply from how it is written. This divergence can manifest in various ways, such as differences in query patterns, expected output formats, or operational scales.
I recounted a personal experience with this challenge in a previous post. The order management system I was developing was optimized for processing entity IDs (like order ID and item ID). However, as time progressed, complex reading requirements arose that the data model couldn't support. There were two main issues: new query patterns emerged that were hard to implement efficiently within the existing structure, and the stakeholders who read order data started to expect a markedly different data representation. For instance, sellers on an e-commerce platform wanted their segments of customer data displayed in a specific format, while customer-facing applications desired the data to resemble its presentation in the cart.
Such occurrences are common, particularly for systems that manage an organization’s core entities. The data they hold is often so widely utilized that it must be available in various formats. The system itself also requires a representation of its data.
Section 1.2: Bridging the Gap with CQRS
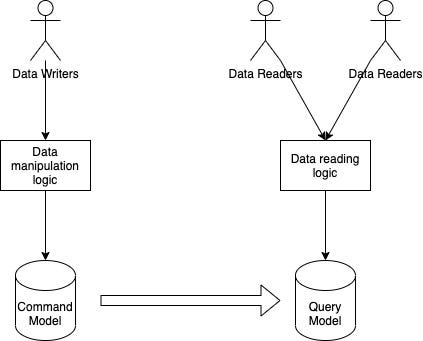
CQRS, which stands for Command Query Responsibility Segregation, is a pattern that addresses these issues. It differentiates between the data models used for Commands (writing data) and Queries (reading data). The command model is optimized for efficient write/update operations, while the query model is tailored to accommodate diverse read patterns. Synchronization between these two models occurs through domain events or other methods, ensuring that changes in the command model reflect in the read model.
If this concept resembles two distinct microservices, it's important to note a subtle distinction. The implementation of these two data models can indeed be structured as separate microservices. A single command model might also support multiple query models. However, a defining feature of microservice architecture is that two microservices typically represent independent domains. In contrast, both command and query models in CQRS belong to the same logical domain, regardless of their runtime architecture. The query model relies on an in-depth understanding of the command model, creating an expected coupling as opposed to the decoupled nature we strive for in separate microservices.
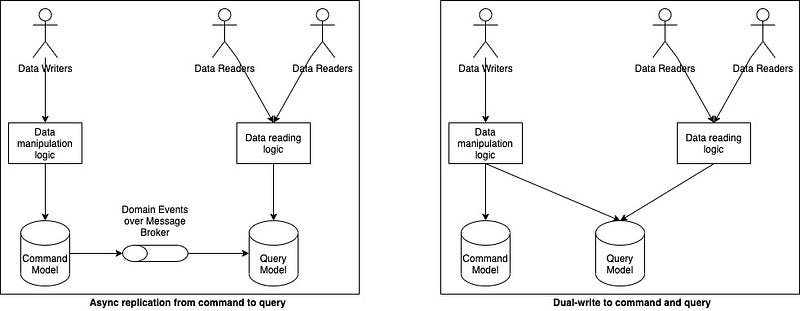
CQRS doesn't prescribe a specific method for maintaining synchronization between the two models. This can be achieved synchronously by updating both models simultaneously or asynchronously by sending commands from the command model to the query model via a message broker like Kafka. The latter option is frequently chosen for its scalability, although it introduces the trade-off of eventual consistency between writing and reading actions.
Chapter 2: Distinguishing CQRS from Caching
A data model that is exclusively dedicated to reading might seem like a cache. While the query model can indeed utilize caching technologies such as Redis, the core objective of CQRS extends beyond merely separating write and read locations. The primary goal is to create multiple representations of the same data, each tailored to specific user requirements. A CQRS architecture can encompass numerous query schemas, each potentially employing different physical implementations; some might utilize the same database, while others could leverage Redis or similar technologies.
Section 2.1: When to Adopt CQRS
CQRS is particularly beneficial in a couple of scenarios. The first scenario arises when the same data model struggles to effectively meet both read and write patterns. In such cases, decoupling the two schemas through CQRS allows the resulting data models to cater to their distinct requirements. CQRS effectively liberates data from a single representation, enabling multiple (read) representations, all consistent with the core model that handles updates.
The second scenario where CQRS proves advantageous is in balancing read and write loads. While it might seem contradictory after previously distinguishing caching from CQRS, consider this: CQRS does not prioritize caching as an end goal. However, by segregating the command and query schemas, we can scale one independently from the other. The query schema might reside on a different database and implement its own caching, allowing the command model to remain unaffected by the scaling needs of the query model. It’s crucial to reiterate that despite this independence, the systems are not truly separate; the coupling between them remains deep and integral.
Section 2.2: The Downsides of CQRS
Implementing CQRS introduces significant cognitive overhead and complexity. Rather than working with a single data model and technology, developers now face at least two data models and potentially multiple technology choices. This added complexity cannot be overlooked.
Another challenge lies in keeping the command and query data models synchronized. Choosing asynchronous updates forces the system to grapple with the implications of eventual consistency, which can be particularly problematic when parts of the system are directly interfacing with users who expect immediate data reflection. A single requirement for consistency can jeopardize the entire design.
Conversely, if we opt to maintain consistent states at all times, we encounter the CAP theorem and the complexities of two-phase commits. If both schemas reside within a single ACID-compliant database, we may still use transactions to ensure consistency. However, this approach diminishes many of the scaling benefits of CQRS. Additionally, if multiple query models need support, the write operations will increasingly slow down, as they must update all query models before completion.
Both of these challenges make the implementation of CQRS a significant undertaking that should be approached with caution. When applied judiciously, it can yield a highly scalable application. However, managing multiple data models is intricate and should only be considered when no other solutions can meet the necessary query patterns.
In this video, the CQRS design pattern is explored in-depth, offering insights into its implementation and practical applications within software architecture.
This brief video explains CQRS in just five minutes, providing a concise overview of what it is and why it matters in modern software development.