Effective Strategies for Enhancing Data Quality with Python
Written on
Understanding Data Quality Challenges
Poor data quality can severely impact the accuracy of our reports, leading to frustration among data scientists and engineers. More importantly, it erodes the trust between data providers and users. When efforts to resolve these issues are made, data teams often address problems downstream rather than at the source.
So, what leads to this situation, and how can we effectively address it?
How Poor Data Enters Our Systems
Consider your last experience submitting a product review. Did you pay attention to the grammar, capitalization, or spelling in your review? Errors in these reviews can lead to flawed data being stored.
Additionally, less obvious sources of erroneous data can infiltrate databases. For instance, when registering for a video game, think about the birthdate you enter. If someone inputs 01-01-1850 (implying they're 172 years old), it's unlikely that a person of that age would be playing video games—if they were even alive.
Data Profiling: A First Step
Data profiling is an essential technique for identifying poor data quality. It involves analyzing datasets to uncover patterns, outliers, and key characteristics that predict outcomes. This process also highlights variables with missing values, allowing for remediation of gaps.
A typical data profile can resemble the following example:
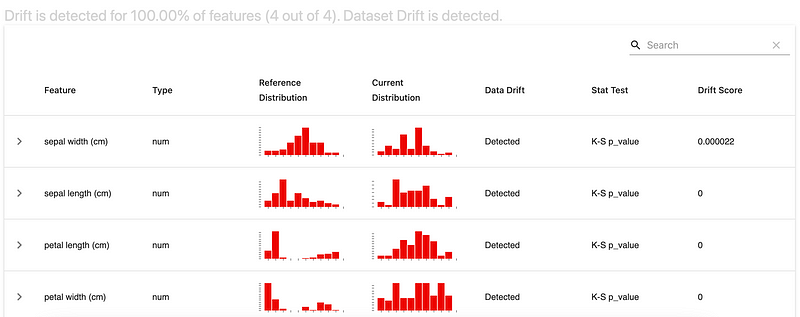
Tools like EvidentlyAI can assist in logging data and concept drift, which is vital for maintaining data integrity.
Data drift occurs naturally over time, whether it's a surge in user counts due to a popular game or a minor bug affecting averages. Identifying these changes early allows for timely solutions before they impact users.
Establishing Data Contracts
The second step is to implement data profiles and create data contracts. A data contract is a mutual agreement between developers and data consumers about the expected values exchanged.
For instance, if a column's minimum date is 1900-12-31 and the maximum is 1999-12-31, you can use a function to flag out-of-bounds data:
def check_contract(date: datetime, max_date: datetime, min_date: datetime) -> str:
if date > max_date or date < min_date:
return 'out'else:
return 'in'
Filtering out-of-bounds data helps identify the reasons behind these anomalies.
Identifying Anomalies
Anomaly detection is the final and most critical method for ensuring data quality. An anomaly is any occurrence that diverges from expected behavior, often represented in a normal distribution.
Normal distributions possess characteristics such as:
- The mean and median are identical.
- 68% of values lie within one standard deviation of the mean.
- 95% of values fall within two standard deviations.
- 99.7% are within three standard deviations.
Values beyond this "three-sigma rule" are considered anomalies. While detecting outliers in single or dual-feature datasets is straightforward, it becomes complex with multiple variables. Machine learning algorithms, like K-nearest neighbors, Local Outlier Factor, and Isolation Forest, can effectively identify these outliers.
K-Nearest Neighbors (KNN) is a commonly used technique that examines the density of data points to pinpoint anomalies.
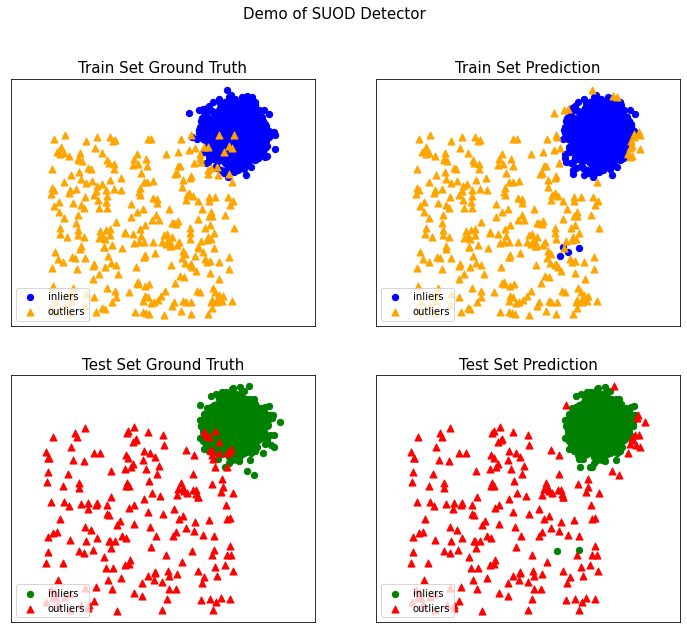
Despite some incorrect predictions, KNN achieves high recall and precision rates.
Conclusion
Anomaly detection, coupled with data profiling and contracts, forms a robust strategy for combating poor data quality. By implementing these methods, organizations can enhance the accuracy and reliability of their datasets.
For further insights, check out the following videos:
Performing Data Quality Checks with Python and SQL from a Power BI SQL Endpoint - This video provides practical examples of how to ensure data integrity.
The Wonderful World of Data Quality Tools in Python - Explore various tools available for maintaining high data quality.